
در این مطلب می خواهیم بررسی کنیم که شبکه های عصبی کانولوشنی چگونه می توانند تصاویر و محتوای آن ها را تشخیص دهند.
همانطور که حدود ۱۰۰ سال پیش الکتریسیته تقریبا همه چیز را دگرگون کرد، امروزه نیز به سختی می توان صنعتی را در نظر گرفت که هوش مصنوعی تا چند سال آینده آن را دگرگون نکند. – اندرو انگ
تشخیص تصاویر یعنی چه؟
یک تصویر دیجیتالی در واقع شمایی از داده های بصری است که به صورت شبکه ای نمایش داده شده است. این شبکه متشکل از مقادیر عددی برای نمایش میزان روشنایی و رنگ هر پیکسل است.
تشخیص تصویر پروسه ای است که در طی آن، تصویری به عنوان ورودی دریافت می شود و پس از عبور از شبکه عصبی، یک کلاس (دسته بندی) از آنچه که درون تصویر است، به عنوان خروجی، ارائه می شود. این کلاس در واقع دسته بندی ای است که از قبل به شبکه عصبی آموزش داده شده و شبکه آن را فرا گرفته است.
این پروسه چگونه انجام می شود؟
بیایید اول نحوه تشخیص تصاویر در مغز انسان ها را بررسی کنیم.
وقتی که ما یک تصویر را توسط چشمانمان می بینیم، حجم عظیمی از اطلاعات تصویری به مغز ما ارسال می شود و در مغز، نرون های عصبی بی شماری هر کدام بخش خاصی از این اطلاعات را پردازش کرده و نتیجه را به نورون های مجاور خود ارسال می کنند. پس از پردازش اطلاعات توسط نورون ها در مورد چیستی محتوای تصویر تصمیم گیری می شود.
شبکه های عصبی مصنوعی (ANN) نیز با الهام گیری از مغز انسان، این پروسه را تقلید می کنند.
یک شبکه عصبی کانولوشنی یا CNN نوعی از شبکه های عصبی است که مخصوص پردازش داده های شبکه ای مانند تصاویر ساخته شده. در این شبکه، چندین لایه وجود دارد تا ابتدا الگو های ساده تر تصاویر (مانند خط ها، انحنا ها و…) تشخیص داده شوند. سپس الگو های پیچیده تر (مانند چهره و اشیا و..) شناسایی می شوند.
فرض کنید یک تصویر رنگی با عرض ۳۲ پیکسل و طول ۳۲ پیکسل به شبکه CNN داده می شود. هر تصویر رنگی از ۳ کانال رنگی قرمز، سبز و آبی تشکیل می شود. پس ورودی شبکه یک ماتریس [۳۲x32x3] خواهد بود.
ماتریس داده شده به CNN باید برای شناسایی شدن اطلاعات آن، از لایه های مختلف شبکه CNN عبور کند. بیایید با این لایه ها آشنا شویم.
لایه های شبکه عصبی کانولوشنی
لایه کانولوشن
این لایه بخش اصلی این نوع شبکه عصبی است. در این لایه، بین دو ماتریس فیلتر یا کرنل که شامل پارامتر ها یا وزن های قابل یادگیری است و ماتریس تصویر، ضرب نقطه ای انجام می شود. ماتریس فیلتر از نظر ابعاد از ماتریس تصویر کوچک تر است. به همین دلیل برای انجام عمل کانولوشن ماتریس فیلتر روی ماتریس تصویر جابجا می شود (اصطلاحا می لغزد) و با انجام ضرب نقطه ای، مقادیری برای تشکیل ماتریس خروجی ایجاد می گردد.
به شکل زیر توجه کنید :
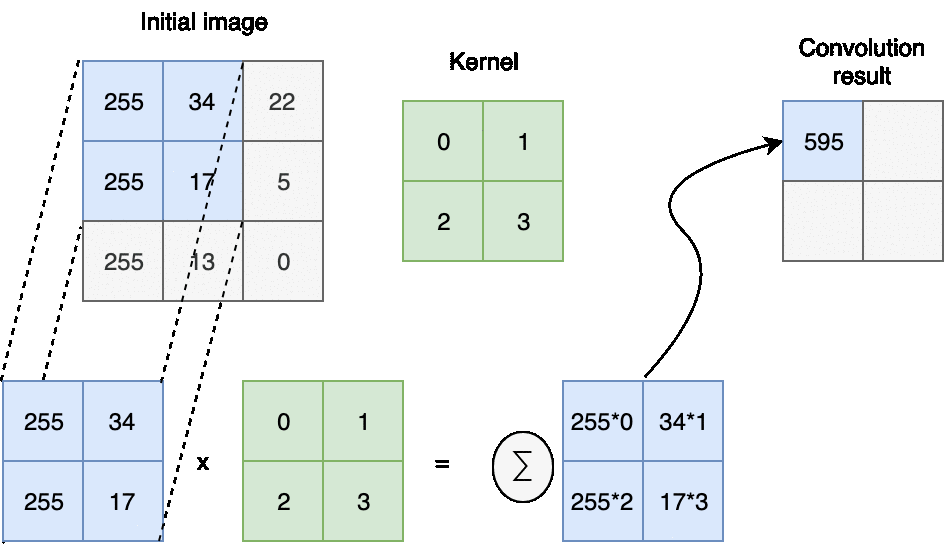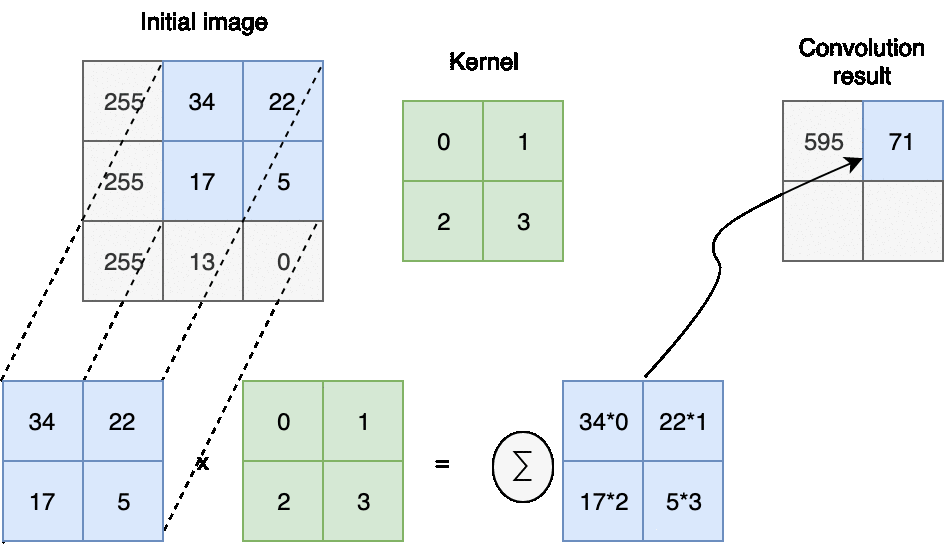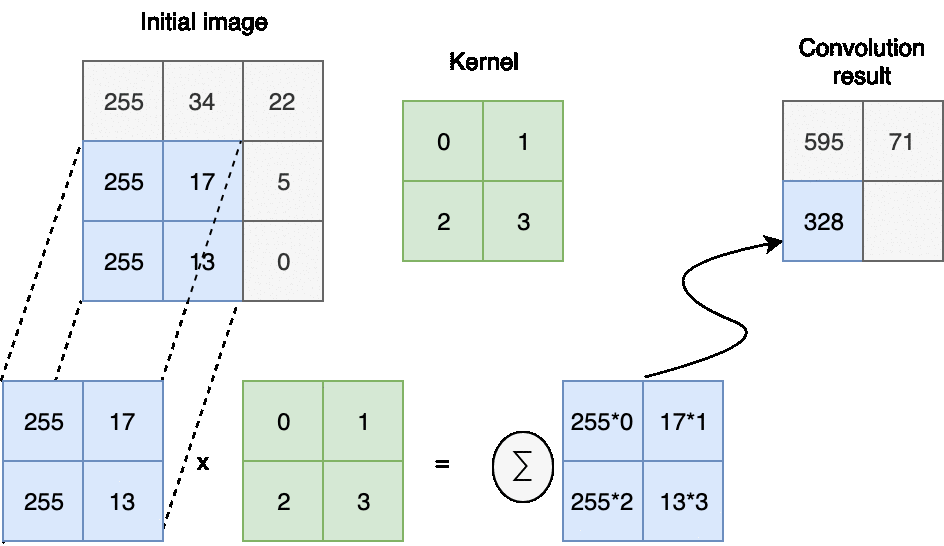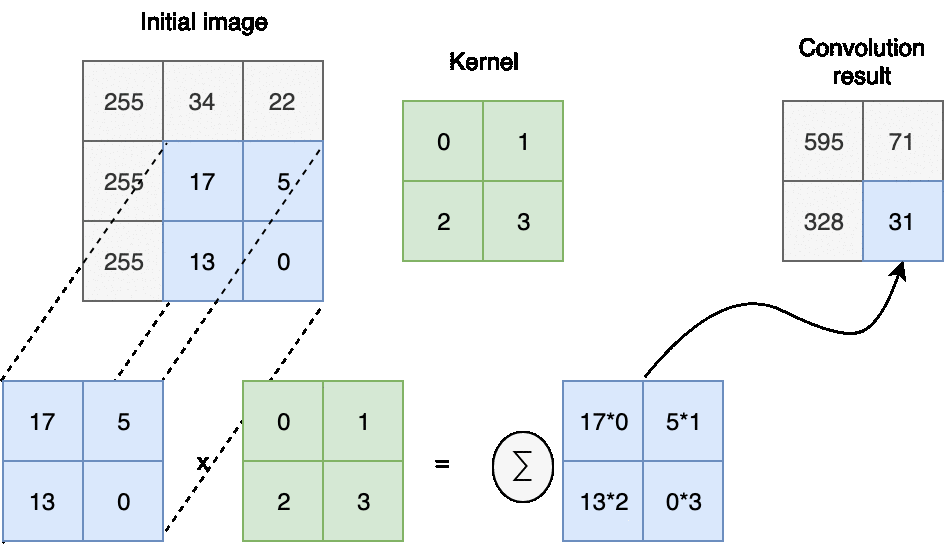
مزایای لایه کانولشنی :
- تعامل پراکنده : این اتفاق وقتی رخ می دهد که اندازه فیلتر از تصویر اصلی کوچک تر باشد. در نظر بگیرید که تصویر ورودی ما شامل هزاران پیکسل است. با انجام کانولوشن می توان اطلاعات مفید این تصاویر را به ده ها یا صد ها پیکسل کاهش داد. در نتیجه ما پیکسل های کمتری خواهم داشت که فضای کمتری برای ذخیره سازی احتیاج دارند و بهینه تر عمل خواهند کرد.
- اشتراک پارامتر ها : فیلتر اعمال شده روی بخش های مختلف پارامتر های یکسانی دارد و مشترک بودن این پارامتر ها در نتایج خروجی این اطمینان را به ما می دهد که تمامی بخش های تصویر با اهمیت یکسانی بررسی شده اند.
- خروجی متعادل : به دلیل این که فیلتر به طور ثابتی روی تصویر حرکت می کند، اگر ما تصویر ورودی را به هر نحوی تغییر دهیم، خروجی نیز به طور مشابهی تغییر خواهد کرد.
لایه پولینگ
لایه پولینگ (Pooling Layer) کمک می کند تا اندازه خروجی را با خلاصه برداری از پارامتر های نزدیک به هم خروجی، کاهش یابد. این کار باعث کاهش بار پردازشی سیستم می شود. توابع مختلفی برای انجام پولینگ وجود دارد که می توان از میان آن ها به میانگین چارچوب مستطیلی، نرم L2 چارچوب مستطیلی و میانگین وزن دار بر اساس فاصله از پیکسل میانی اشاره کرد. معروف ترین آن ها Max Pooling است که مقدار ماکزیمم پارامتر های موجود در هر چارچوب را انتخاب می کند.
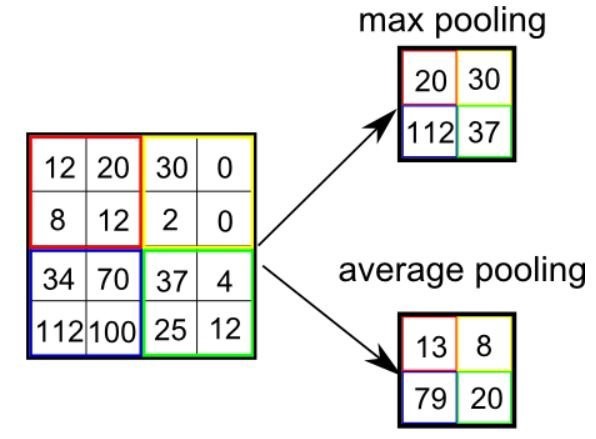
لایه تماما متصل
لایه تماما متصل یا Fully Connected متشکل از مجموعه ای از نرون ها، وزن ها و بایاس ها است. منظور از تماما متصل این است که در این لایه هر نرون به تعدادی از نرون های لایه بعد متصل است که در نهایت همه این نرون ها را به خروجی متصل می کند. لایه های تماما متصل معمولا در انتهای شبکه و پیش از نتیجه گیری نهایی قرار می گیرند و بخش اعظمی از معماری CNN را به خود اختصاص می دهند.
در لایه تماما متصل CNN ها، تصویر ورودی پس از گذر از لایه های قبلی به صورت مسطح (Flat) وارد لایه تماما متصل می شود. بردار مسطح از چندین لایه عبور می کند که در هر کدام از آن ها عملیات های ریاضی مختلفی روی آن انجام می شود. پس از گذر از لایه تماما متصل، به بخش کلاسه بندی می رسیم.

حذف تصادفی (Dropout)
معمولا وقتی که تمام ویژگی ها در لایه تماما متصل به هم وصل می شوند، روی دیتاست آموزش بیش برازش (Overfitting) اتفاق می افتد.
بیش برازش وقتی اتفاق می افتد که یک مدل روی مجموعه داده های آموزش خود بیش از حد بهینه شود و در این حالت وقتی که مدل می خواهد با داده های جدید کار کند، به مشکل می خورد.
برای رفع این مشکل، یک از لایه باز دارنده استفاده می شود تا برخی نرون ها را در مرحله آموزش از شبکه عصبی خارج کند. مثلا وقتی شما مقدار ۰٫۳۵ را برای این لایه تعریف کنید، ۳۵% نرون های شبکه به طور تصادفی حذف می شوند.
تابع فعال سازی
در نهایت، مهم ترین بخش هر مدل CNN تابع فعال سازی است. تابع فعال سازی برای یاد گیری و تخمین هر گونه روابط مستتر و پیچیده میان متغیر های شبکه است.
به طور ساده می توان گفت وظیفه این لایه در راس مدل وظیفه دارد مشخص کند کدام اطلاعات باید به مراحل و لایه های بعدی ارسال شوند و کدام اطلاعات بی اهمیت هستند.
این لایه می تواند ویژگی های غیر خطی به شبکه اضافه کند. توابع فعال سازی معمول عبارت اند از ReLU ، Softmax ، tanH و توابع سیگموئید.
هر کدام از این توابع، کاربرد های متفاوتی دارند. برای یک کلاسه بندی دودویی (دو کلاس) با مدل CNN ، توابع فعال سازی سیگموئید و Softmax مناسب اند و برای کلاسه بندی چند حالته، معمولا Softmax انتخاب می شود.
برخی از توابع فعال سازی در ادامه معرفی شده اند :
- ReLU – تابع ReLU یا Rectified Linear Unit بدین صورت کار می کند که تمامی مقادیر منفی را صفر می کند و مقادیر مثبت را بدون تغییر نگه می دارد. در واقع تمام مقادیر منفی را خنثی می کند.
- سیگموئید – مقدار ورودی تابع به مقادیری بین ۰ تا ۱ تغییر پیدا می کند. یعنی مقادیر بیشتر از ۱ به ۱ تغییر کرده و مقادیر کوچک تر از ۰ به صفر تغییر پیدا می کنند.
- تانژانت هایپربولیک (tanH) – تابع تانژانت هایپربولیک تابعی مشابه سیگموئید و غیر خطی است که مقادیر را بین ۰ و ۱ بر می گرداند.
- Softmax – تابع فعال سازی Softmax احتمالات نسبی را محاسبه می کند. می توان آن را حالت بهینه شده ی سیگموئید دانست.
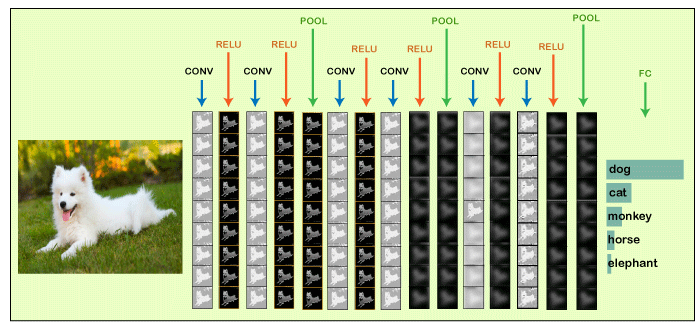
تفاوت CNN و شبکه های عصبی معمولی چیست؟
یک شبکه عصبی معمولی تصویر را به لیستی از پیکسل ها تبدیل می کند که با یک دیگر در ارتباط نیستند و بدین صورت ممکن است برخی اطلاعات مربوط به مجاورت پیکسل ها از بین برود. اما در مقابل شبکه CNN یک لایه کانولوشنی ایجاد می کند که اطلاعات مربوط به مجاورت پیکسل ها را نیز نگه می دارد.
جمع بندی
تشخیص تصاویر با یادگیری عمیق کاربرد های بسیاری دارد. از جمله آن ها می توان در بهبود بازی ها و برنامه های واقعیت افزوده، کمک در سیستم آموزش، بهینه سازی تصویر برداری پزشکی، پیش بینی رفتار مصرف کنندگان و بینایی ماشین اشاره کرد.
در این مطلب تنها با مقدمات و برخی اصطلاحات شبکه تشخیص تصاویر با شبکه های CNN صحبت کردیم. کاربرد هایی که ذکر شد نیز تنها برخی از بیشمار کاربرد خلاقانه ای است که می توان از طریق این مدل ها ارائه کرد تا بتوان سطح تکنولوژی و زندگی روزمره را بهبود بخشید.
بیشتر بخوانید :




یک نظر
دنبال کنید : 13 کاربرد هوش مصنوعی در حوزه فناوری واقعیت افزوده در سال 2022 - مجله شهاب