
در بحث شناسایی اشیا در یک تصویر ، شناسایی چندین شی در یک تصویر به طور هم زمان هم چنان دارای چالش عملیاتی است. با جستجوی مناطق دارای مفوم مشترک و بهره برداری از وابستگی اشیا مختلف با یکدیگر ، پیشرفت ها چشمگیری در این زمینه حاصل شده است.
اگرچه، پژوهشهای فعلی با استفاده از شبکه های RNN / LSTM مناطق متوالی ای که دارای وابستگی معنایی باشند را ضبط می کند، اما نمی توانند تعاملات متقابل بین اشیا مختلف را به طور کامل کشف کنند. علاوه بر این، این آثار به مقدار زیادی نمونه آموزشی برای هر دسته نیاز دارند و قادر به تعمیم به دسته های جدید با نمونه های محدود نیستند.
برای پرداختن به این مسائل، ما یک چارچوب نمودارسنجی هدایت شده توسط دانش (KGGR) را پیشنهاد می کنیم، که دانش قبلی در مورد همبستگی آماری کلاس های مختلف را با شبکه های عصبی عمیق پیوند می دهد. این فریمورک دانش قبلی را برای هدایت انتشار اطلاعات انطباقی در بین دسته های مختلف برای تسهیل تجزیه و تحلیل چند کلاس مختلف و کاهش وابستگی به نمونه های آموزشی به کار می گیرد.
ما آزمایشات گسترده ای در مورد وظایف شناسایی تصاویر چند کلاسه (MLR) و یادگیری چند شات (ML-FSL) انجام می دهیم و نشان می دهیم که چارچوب KGGR ما نسبت به روش های حال حاضر، قدرت تعمیم مناسبی دارد.
طرح مساله
تصاویر دنیای واقعی به طور کلی شامل اشیایی هستند که به چندین دسته متنوع تعلق دارند. یه طور کلی، مقوله شناسایی چندین شی در تصاویر مبحثی پیچیده تر در مقایسه با بازشناسی تصویر تک شی در دید کامپیوتر است.
اخیراً، محققان تمرکز خود را در ایجاد یک سری الگوریتم برای تجزیه و تحلیل تصاویر با چندین شی مختلف بیشتر کرده اند که زیربنای بسیاری از برنامه های مهم مانند بازیابی تصویر مبتنی بر محتوا و یا مبتنی بر سیستم های پیشنهادی دیگر است. علیرغم این دستاوردها ، شناسایی وجود چندین دسته معنایی نه تنها مستلزم استخراج ناحیه های معنایی متنوع است، بلکه همچنین ارتباط دادن این مناطق بایکدیگر از لحاظ معنایی، تجزیه و تحلیل تصویر چند چند کلاسه را به یک کار چالش برانگیز و حل نشدنی تبدیل می کند.
رویکردهای فعلی به طور عمده از تکنیکهای مکانیابی اجسام و یا مکانیسمهای توجه دیداری برای تشخیص نواحی با مقولههای معنایی معتبر استفاده میکنند. با این حال، تکنیکهای مکانیابی اجسام نیازمند است تا جست و جوی بسیاری در مورد مناطق مهم و هم چنین مناطق زائد که فاقد اطلاعات مهم است انجام شود. این امر باعث بروز مشکل در شبکه های عمیق می شود.
علاوه بر این، مکانیزم توجه بصری به دلیل فقدان نظارت و هدایت صریح، به طور دقیق مناطق هدف معنایی را تعیین نمیکند. اغلب پژوهش ها اخیر به طور ضمنی از مدلهای RNN / LSTM را برای شناسایی وابستگیهای متنی در مناطق تعیین شده و در نتیجه وابستگیهای بین اشیا استفاده کرده اند.
با این حال، این الگوریتم ها فقط وابستگی های بین نواحی تصویر و برچسب آن را مدل می کنند. آنها نمی توانند به طور کامل از این ویژگی بهره برداری کنند زیرا بین هر ناحیه و برچسب آن وابستگی مستقیم وجود دارد. علاوه بر این، آن ها صریحاً همبستگی آماری بین دسته ها را که راهنمایی مستقیم و کلیدی برای کمک به تجزیه و تحلیل تصویر با چند برچسب است، ادغام نمی کنند.
روش های فعلی برای یادگیری ویژگی های تصویر از شبکه های کانولوشن عمیق استفاده می کنند. چنین شبکه هایی نیاز به تعداد زیادی نمونه آموزش برای هر دسته دارند و قادر به تعمیم به دسته های جدید با نمونه های محدود نیستند.
برای حل این مسئله، محققان اخیراً مجموعه ای از الگوریتم های یادگیری چند باره را ایجاد کرده اند که می توانند پس از آموزش در یک دسته پایه با نمونه های آموزش کافی، دسته های جدیدی را بیاموزند. این الگوریتم ها از الگوی فرایادگیری استفاده می کنند، برای کمک به یادگیری دسته های جدید از تقطیر دانش به دست آمده از دسته های با نمونه های آموزش کافی، یا استفاده از فن آوری های ترکیب نمونه برای ایجاد نمونه های متنوع بیشتر برای دسته های جدید، کمک می گیرند.
اگرچه این تکنیک ها پیشرفت چشمگیری داشته اند، اما بیشتر بر روی سناریوهای تک برچسب تمرکز دارند تا موارد کلی که دارای چند برچسب باشند.
اشیا در صحنه های بصری معمولاً همبستگی های شدیدی دارند. به عنوان مثال، میز ها معمولاً با صندلی ها همخوانی دارند، یا رایانه ها معمولاً با کیبوردها دیده می شوند. این همبستگی ها می تواند راهنمایی بیشتری برای گرفتن برهم کنش بین گروه های مختلف داشته باشد و بنابراین تجزیه و تحلیل چند کلاسه را، به ویژه برای سناریو های پیچیده و با داده های اندک تسهیل می کند.
در این کار ، ما نشان می دهیم که همبستگی های معنایی را می توان به طور صریح توسط یک نمودار دانش ساختاری نشان داد و چنین تعاملی را می توان به طور موثر با گسترش اطلاعات از طریق نمودار به دست آورد. برای این منظور، ما چارچوبی با آگاهی از راهنمای نمودار (KGGR) را پیشنهاد می دهیم تا به به یادگیری بیشتر تصاویر دارای مفاهیم متفاوت کمک کند و با انتشار اطلاعات معنایی از طریق دسته های مختلف، آموزش طبقه بند ها را تسهیل کند.
چارچوب KGGR چیست؟
چارچوب KGGR یا knowledge-guided graph routing بر روی دو شبکه انتشار ایجاد می شود که انتشار پیام را بر روی ویژگی ها و فضا های معنایی انجام می دهند. به طور خاص، ابتدا یک نمودار بر اساس برهم کنش آماری کلاس ها ایجاد می کند تا بین گروه ها و یا همان برچسب های مختلف ارتباط و هم بستگی ایجاد کند.
برای فضای ویژگی ما یک ماژول راهنما از لحاظ معنا و مفهوم، طراحی کردیم که مفاهیم را برای راهنمایی اموزش ویژگی های تصویر مختص به یک کلاس که بر روی ناحیه معتبر با مفهوم متمرکز هستند، اعمال می کند. با مقدار دهی اولیه گره گراف با بردار ویژگی های دسته مربوطه، ما یک شبکه انتشار معرفی می کنیم تا ویژگی ها را در گراف انتشار دهیم تا از این طریق برهم کنش و وابستگی ویژگی ها را ثبت کند و ویژگی های مفهومی را یاد بگیرد.
با توجه به فضای معنایی، ما هر گره را به عنوان وزن طبقه بند در هر گروه در نظر می گیریم و با استفاده از شبکه تکثیر گراف دوم عمل انتقال پیام در گره های گراف را انجام داده و از اطلاعات در کلاس های مختلف برای بهبود فرایند اموزش کمک بگیرد.
نسخه مقدماتی این کار به عنوان مقاله کنفرانس ارائه شد. در این نسخه، ما یکپارچه سازی همبستگی کلاس های آماری را با شبکه های انتشار گراف عمیق انجام می دهیم و چارچوب را از چندین جنبه زیر تقویت می کنیم.
اول، ما اطلاعات را در هم درفضای ویژگی و هم در فضای معنایی انتشار می دهیم، که باعث یادگیری ویژگی های قدرتمندتر زمینه می شود و به طور همزمان وزن های طبقه بند را منظم می کند.
دوم، ما چارچوب پیشنهادی را به طور کلی برای چالش کشید یادگیری چند برچسب با داده اندک تعمیم می دهیم و برتری خود را در این کار نشان می دهیم. سرانجام ، ما آزمایشات و تجزیه و تحلیل های گسترده تری را در مورد چندین معیار گسترده انجام داده و ضمن تأیید سهم هر یک از مولفه ها، اثربخشی چارچوب پیشنهادی را نشان می دهیم.
به طور خلاصه، دستاورد این کار را می توان به شرح زیر جمع بندی کرد:
- ما یک چارچوب جدید برای هدایت نمودار (KGGR) با راهنمایی دانش ارائه می دهیم که کنش متقابل گروه ها را در هر دو فضای ویژگی و معنایی تحت راهنمایی آماری گروه ها را بررسی می کند. این روش می تواند به شما در یادگیری ویژگیهای متناسب با قدرت بیشتر و تنظیم وزن های طبقه بند کمک کند.
- ما یک مکانیسم توجه ساده و هدایت شونده را ارائه می دهیم که از مفاهیم کلاس ها برای بهره گیری از ویژگی های معنایی متمرکز در نواحی معتبر و معنب دار تصویر بهره برداری می کند.
- ما از چارچوب KGGR استفاده می کنیم تا هم به شناسایی تصویر چند کلاسه و هم به یادگیری با داده اندک بپزدازیم و آزمایشاتی را با معیارهای مختلف انجام می دهیم ، از جمله Visual Genome, Microsoft-COCO , PASCAL2007 & 2012 که کلاس های در مقیاس بزرگ دارند، و نشان می دهیم که چارچوب ما پیشرفت های اساسی داشته است.
روش پیشنهادی
در این بخش ، ما یک تعریف کلی از چارچوب پیشنهادی KGGR ارائه می دهیم. این چارچوب بر اساس گرافی طراحی شده است که دانش پیشین مربوط به همبستگی کلاس ها را رمزگذاری می کند. سپس، دو شبکه انتشار نمودار را معرفی می کند که اطلاعات را در هر دو فضای ویژگی و معنایی منتشر می کند.
برای انتشار ویژگی، چارچوب ابتدا تصویر ورودی را به یک شبکه کاملا کانولوشنی برای تولید نقشه ی ویژگی ها می دهد که مفاهیم و شامل مفاهیم دسته ها می شود با این کار یادگیری فضای معانی وبردار ویژگی هایی که برای هر دسته بر روی نواحی معنب دار تصویر تمرکز کرده اند اسان تر خواهد شد. سپس، گره های گراف را با بردارهای مشخصه مربوطه مقداردهی اولیه می کند و یک شبکه انتشار گراف را برای بررسی ویژگی های متقابل پیاده سازی می کند.
برای انتشار معنایی، هر گره با وزن طبقه بند دسته مربوطه مقدار دهی می شود. سپس، یک شبکه انتشار گراف دیگر اموزش داده شده است که پیام های گره را از طریق نمودار به صورت منتشر می کند تا فعل و انفعالات گره را بررسی کند و اطلاعات طبقه بند را از گروه های وابسته به هم انتقال دهد تا به ما در کمک به آموزش طبقه بندی ها کمک کند. طرح کلی در شکل زیر نشان داده شده است.
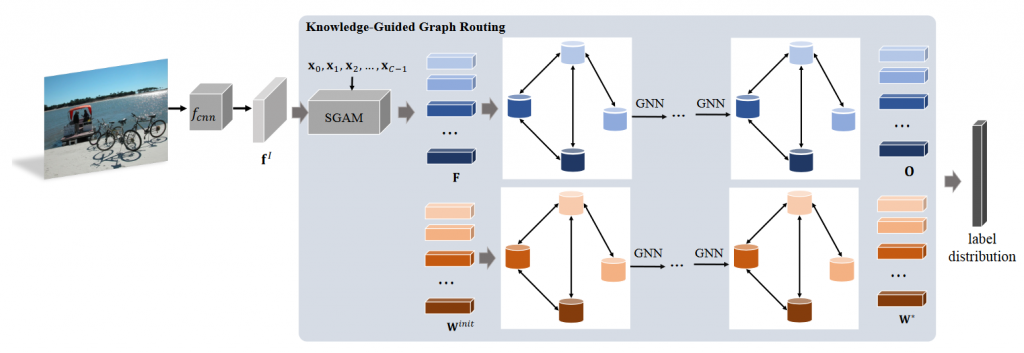
ساخت نمودار دانش
ما ابتدا نمودار دانش G = {V,A} را معرفی می کنیم که در آن گره ها نمایانگر دسته ها و لبه ها نشان دهنده همدستی بین دسته های متناظر هستند .به طور خاص، فرض کنید که در یک مجموعه داده که شامل C دسته باشد، V را می توان به این شکل در نظر گرفت V = { v0, v1,…, vc-1} که در آن مولفه vc نشان دهنده دسته c ام است و A بصورت A = {a00,a01 , …, a(c-1)(c-1) } نمایش داده می شود که مولفه acc’ نشان دهنده احتمال این که یک شی متعلق به دسته c’ است، وقتی که بدانیم یک شی از دسته c داریم. ما احتمالات بین همه دسته ها را با استفاده از تفسیر از نمونه های مجموعه آموزشی محاسبه می کنیم. بنابراین، هیچ تفسیر اضافی ای معرفی نمی کنیم.
مکانیزم توجه هدایت شده معنایی
در قدم اول تصویر به یک شبکه کانالوشنی ارسال می شود تا نقشه ویژگی ها استخراج شود. fI∈RW×H×N که در آن W عرض تصویر، H ارتفاع و N تعداد کانال های تصویر است. این شبکه کانالوشنی به شکل زیر فرموله می شود.
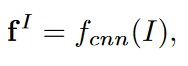
fcnn(⋅) نشان دهنده استخراج کننده ویژگی اجرا شده توسط شبکه کانولوشنی است. برای هر دسته C یک بردار معنایی با بعدd تولید می شود:
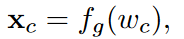
که wc لغت معنایی نمایانگر دسته c است. تا این مرحله بردار معنایی xc تولید شده است. برای هر نقطه w,h در تصویر با استفاده از رابطه زیر ویژگی های تصویر و بردار معنایی را مخلوط می کنیم:
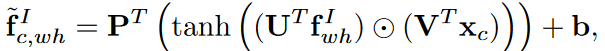
که در آن tanh تانژانت هایپربولیک، U پارامتری قابل اموزش، ⋅ ضرب مولفه به مولفه است. سپس با استفاده از رابطه زیر ضریب توجه محاسبه می شود که نشان دهنده اهمیت نقطه w,h است.
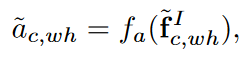
این روند برای تمامی نقاط تکرار می شود و در نهایت ضرایب a به شکل زیر نرمال می شوند.
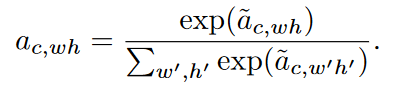
در انتها پولینگ میانگین وزن دار برای تمامی نقاط اجرا می شود تا بردار ویژگی بدست اید
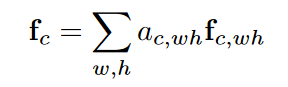
رابظه بالا اطلاعات وابسته به کلاس c را رمزنگاری می کند. این اعمال برای تمای کلاس ها تکرار می شوند تا بردار ویژگی {f0, f1, …, fc-1} بدست اید. در این صورت ما می توانیم یاد بگیریم که ویژگی fc برای کلاس c بر روی چه نواحی متمرکز است.
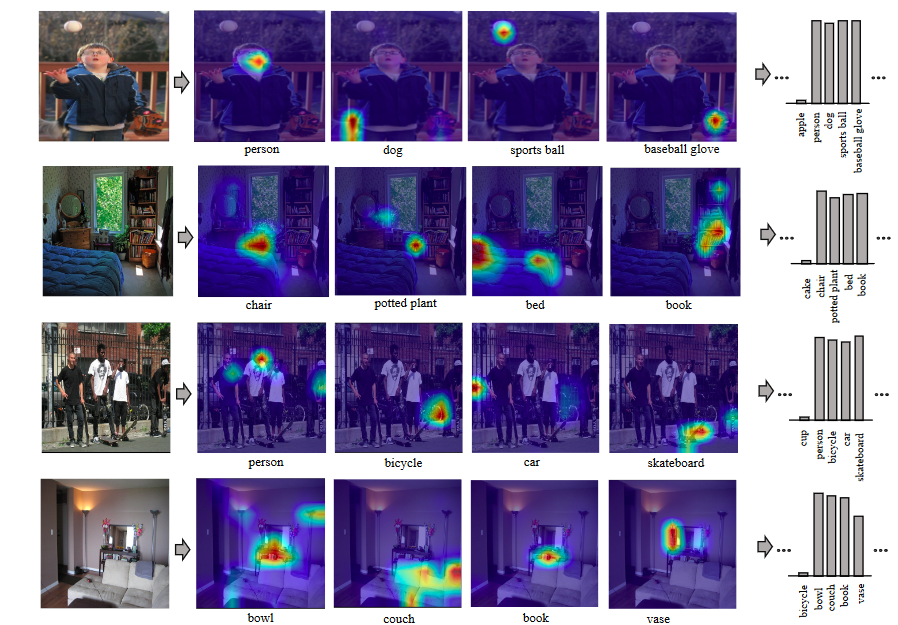
انتشار ویژگی های دانش
پس از به دست آوردن بردارهای ویژگی مربوط به همه دسته ها، ما گره های را با استفاده از بردار ویژگی در گروه مربوطه مقداردهی اولیه می کنیم و یک شبکه گرافیکی عصبی را برای انتشار پیام ها از طریق گراف معرفی می کنیم تا تعاملات آن ها را بررسی کند تا یک بازنمایی متنی را یاد بگیریم.
با استفاده از روش گراف دروازه دار شبکه های عصبی، یک مکانیسم بازگشتی برای انتشار پیام میان گراف پیاده می کنیم تا ویژگی های سطح گره را یاد بگیریم. هر گره vc یک حالت مخفی htc در بازه زمانی t دارد. در زمان صفر این حالت را با fc مقدار دهی اولیه می کنیم.
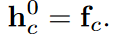
در بازه زمانی t چارچوب، پیام های گره های همسایه را جمع می کند.
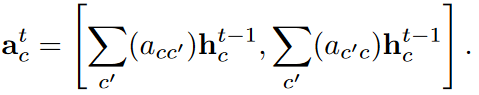
در این روش، چارچوب انتشار پیام را تشویق ی کند اگر گره c’ با گره c همبستگی بالایی داشته باشد، در غیر این صورت انتشار را سرکوب می کند. سپس چارچوب، حالت های مخفی را بر پایه ی بردار ویژگی جمع شده ی atc و حالت قبلی در بازه زمانی t-1 بروزرسانی می کند. مکانیسم بروز رسانی مکانیسم دروازه ای با فرمول بندی زیر است.
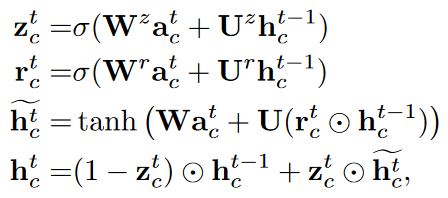
که σ(⋅) تابع سیگموید، tanh تابع تانژانت هایپربولیک و ⋅ ضرب المان به المان است. این روند برای هر بازه زمانی Tf تکرار می شود. حالت های مهایی تولید شده به صورت {hTf0,hTf1,…,hTfC-1} هستند. در نهایت برداری ویژگی ورودی h0C و hTfC به هم ملحق میکنیم تا بردار ویژگی برای هر کلاس بدست اید
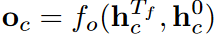
که fo(⋅) تابع خروجی ای است که hTC و h0C را به بردار خروجی Oc نگاشت می دهد.
انتشار نمودار معنایی
یک وزن طبقه بند را می توان الگوی اولیه نمونه مربوطه در نظر گرفت. انتقال الگو های اولیه در میان دسته های مشابه می تواند آموزش طبقه بند را به ویژه برای دسته هایی که نمونه آموزش اندکی دارند، تسهیل کند. برای دستیابی به این هدف، برای دستیابی به این هدف ، نمودار G را تشویق می کنیم تا نسخه نمایشی نمونه اولیه را در میان همه گروه ها هدایت کنیم تا از اطلاعات دسته های همبسته استفاده کامل کرده و آموزش طبقه بندی را بهبود ببخشیم.
به طور خاص، ما هر گره نمودار را با وزن طبقه بندی کننده مربوطه مقداردهی اولیه می کنیم و پیام های گره را به صورت عملی منتشر می کنیم. در هر تکرار t گره Vc حالت مخفی hc را دارد. حالت مخفی hc در زمان صفر با وزن های طبقه بند به شکل زیر مقدار دهی اولیه می شود.
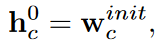
که Wc قبل از اموزش به صورت تصادفی مقدار دهی می شود. در هر دوره t هر گره پیام ها را به صورت فرمول زیر از گره های وابسته خودش جمع اوری می کند.
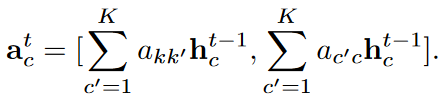
به این ترتیب، همبستگی زیاد بین گره های k و k ′ باعث انتشار پیام از k ′ به k می شود. در غیر این صورت، انتشار را سرکوب می شود. سپس، چارچوب از این بردارهای ویژگی تجمیعی و حالت پنهان تکرار قبلی به عنوان ورودی برای به روزرسانی حالت پنهان از طریق مکانیسم دروازه ای همانند رابطه ۹ استفاده می کند.
به این ترتیب ، هر گره می تواند از طریق گره های دسته های همبسته، پیام بیشتری جمع آوری کند تا طبقه بندی کننده های خود را به روز کند. تکرار بارها تکرار می شود ؛ در نهایت، حالت های پنهان نهایی {hTs0,hTs1,…,hTsC-1} ایجاد می شوند. سرانجام، ما از یک شبکه خروجی ساده برای پیش بینی وزن طبقه بندی استفاده می کنیم.
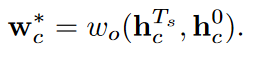
یادگیری چند کلاسه با نمونه های آموزش اندک
برای یادگیری چند برچسب چند برچسب، مجموعه داده شامل مجموعه ای از دسته های پایه Cb با نمونه های آموزشی کافی و مجموعه ای از دسته های جدید Cn با نمونه های آموزش محدود (به عنوان مثال ، ۱ ، ۲ یا ۵).
مرحله اول : در مرحله اول، ما چارچوب را با استفاده از نمونه های آموزشی دسته های پایه آموزش می دهیم. در اینجا، ما Cb دسته داریم و ماتریس مجاورت A را بر اساس اتفاقات مشترک در بین این دسته های Cb می سازیم. از نمونه های Cb، می توانیم بردار نمرات si={si0,si1,…,si(Cb-1)} وبردار احتمال pi={pi0,pi1,…,pi(Cb-1)} را بسازیم و سپس خطا را از رابطه زیر حساب کنیم.
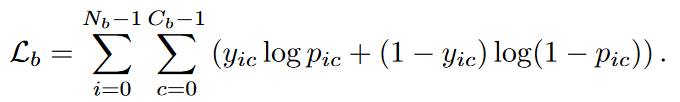
که در آن Nb تعداد نمونه های آموزش پایگاه داده است. به همین ترتیب، پارامترهای شبکه اصلی با پارامترهایی که از قبل روی مجموعه داده ImageNet آموزش می بینند، مقدار دهی اولیه می شوند، در حالی که سایر لایه ها به طور تصادفی مقدار دهی اولیه می شوند. ما همچنین لایه های کانولوشن قبلی را در شبکه اصلی اصلاح کرده و به طور مشترک تمام لایه های دیگر را با استفاده از الگوریتم آدام با اندازه دسته ۴ و مومنتوم های ۰٫۹۹۹ و ۰٫۹ آموزش می دهیم. ما نرخ یادگیری اولیه را ۵-۱۰ تنظیم کردیم و پس از ۱۲ دوره آن را بر ۱۰ تقسیم کردیم. این چارچوب در کل با ۲۰ دوره آموزش دیده است.
مرحله دوم : در مرحله دوم، پارامترهای شبکه اصلی و ماژول های توجه برای استخراج ویژگی ها را تعیین می کنیم و دو شبکه عصبی گراف را با استفاده از مجموعه های جدید آموزش می دهیم. از آنجا که نمونه های آموزشی در این مرحله محدود هستند، ما نمی توانیم همبستگی آماری را برای بدست آوردن ماتریس مجاور محاسبه کنیم. برای پرداختن به این موضوع، ما شباهت معنایی را برای محاسبه همبستگی کلاس ها در نظر می گیریم. به علاوه اینکه ما یک تنظیم کننده وزن جدید معرفی می کنیم و تابع خطا را بصورت زیر معرفی می کنیم.
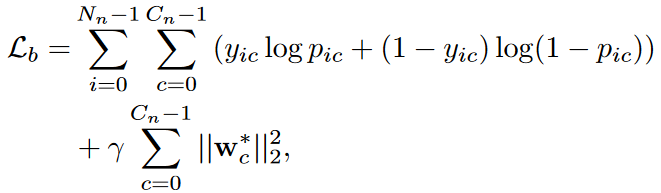
که Nn تعداد داده های اموزش است و ϒ پارامتر تنظیم کننده است که برابر با مقدار ۰٫۰۰۱ قرار داده شده است. ما مدل را با الگوریتم آدام و با همان اندازه سبد و مومنتوم مرحله یک آموزش می دهیم. نرخ یادگیری را ۴-۱۰ قرار داده و آموزش را برای ۵۰۰ دوره انجام می دهیم.
نتایج
تا بدین جا با راه حل پیشنهادی این منبع اشنایی پیدا کردیم. برای تعیین میزان اثر بخشی این روش سراغ نتایج این مقاله و مقایسه ان با دیگر روش ها می رویم.
نویسنده مقاله برای مقایسه روش خود از معیار های زیر کمک گرفته است:
AP: دقت متوسط برای هر گروه
mAP: دقت متوسط برای همه گروه ها
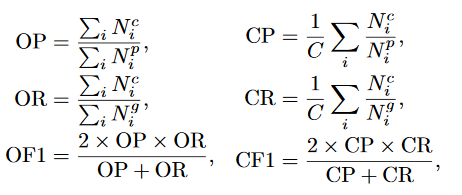
که C تعداد کلاس ها Nci تعداد تصاویری که برای کلاس i ام درست پیش بینی شده است. Npi تعداد تصاویری که به کلاس i ام تخصیص داده شده اند. Ngi تعداد تصاویر درست مرجع برای کلاس i است.
برای آزمایش این روش، تهیه کننده مقاله از مجموعه داده های زیر کمک گرفته است:
Pascal VOC 2007 & 2012 : هر دو دارای ۲۰ کلاس مشترک هستند. Pascal VOC 2007 دارای ۵۰۱۱ تصویر برای اموزش و اعتبار سنجی و ۴۹۵۲ تصویر برای آزمایش است. VOC 2012 دارای ۱۱۵۴۰ تصویر آموزش و اعتبار سنجی و ۱۰۹۹۱ تصویر برای آزمایش است.
Microsoft COCO : این مجموعه داده اصولا برای شناسایی اشیا توسعه داده شده بود اما اخیرا با طبقه بندی چند کلاسه هم منطبق شده است. این مجموعه داده دارای ۱۲۲۲۱۸ تصویر در ۸۰ کلاس است. دارای۸۲۰۸۱ تصویر اموزش و اعتبار سنجی و هم چنین ۴۰۱۳۷ تصویر برای آزمایش است. برای اموزش کلاس جدید با داده اندک مجموعه داده ذکر شده به عنوان ۶۴ کلاس پایه و ۱۶ کلاس جدید در نظر گرفته شده است.
Visual Genome : شامل ۱۰۸۲۴۹ تصویر و ۸۰۱۳۸ کلاس است. از انجا که این مجموعه داده دارای داده های کمی در هر کلاس است، فقط ۵۰۰ کلاس پر تکرار در نظر گرفته شده است. برای این منظور ۱۰۰۰۰ تصویربه صورت تصادفی برای آزمایش و ۹۸۲۴۹ تصویر برای آموزش در نظر گرفته شده است. برای طبقه بندی چند کلاسه، مجموعه به۴۰۰ کلاس پایه و ۱۰۰ کلاس جدید تفسیم شده است.
مقایسه نتایج در مجموعه داده Microsoft COCO
در جدول یک نتایج روش جاری با دیگر روش های مطرح با معیار top-3 یا ۳ نتیجه برتر مقایسه شده است.
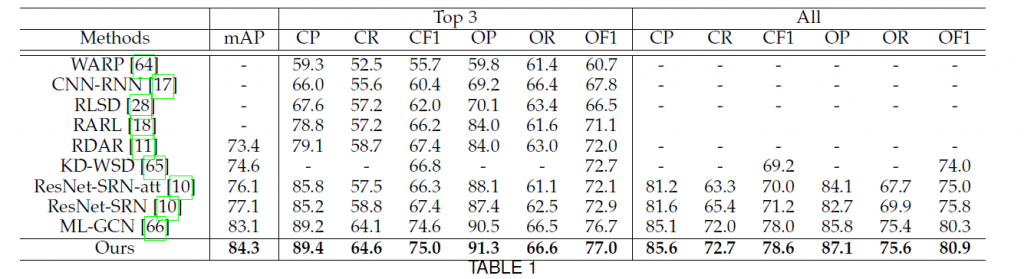
مشاهده می شود که این روش در تمامی معیار ها نسبت به سایر روش ها برتری دارد.
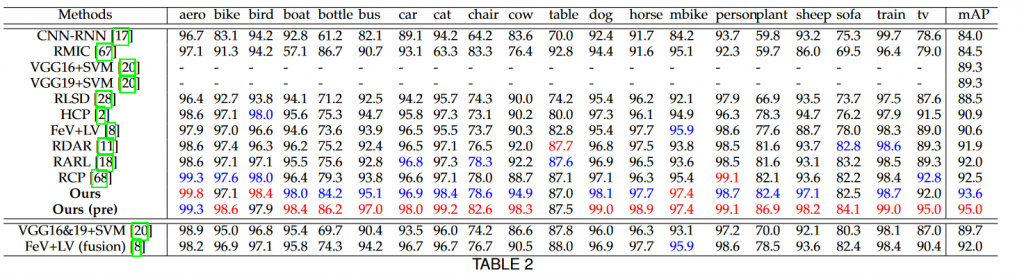
مقایسه نتایج در مجموعه داده PASCAL VOC 2007
در جدول دو نتایج با روش های حال حاضر به تفکیک کلاس مقایسه شده اند. قسمت بالایی جدول برای مدل های تکی و قسمت پایین برای مدل های ترکیبی است. بهترین نتیجه با رنگ قرمز و دومین نتیجه با رنگ آبی مشخص شده است. Ours (pre) نتایج روش جاری که در ان مقادیر اولیه وزن ها از وزن های اموزش دیده با مجموعه داده coco استفاده شده است.
مقایسه نتایج در مجموعه داده PASCAL VOC 2012
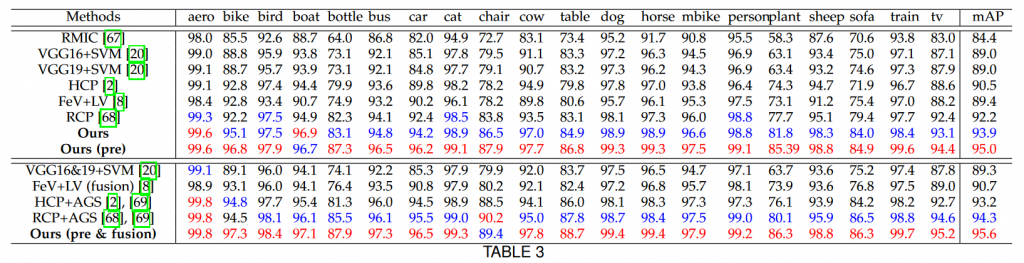
مشاهده می شود در دو مجموعه داده فوق نیز روش جاری در اکثر قریب به اتفاق گروه ها به سیر روش ها برتری دارد.
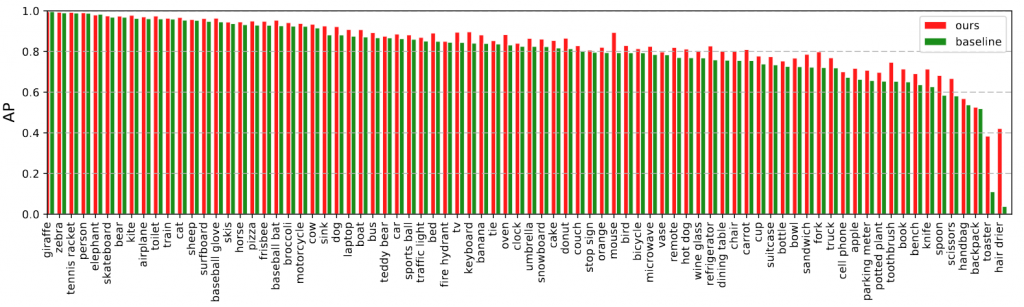
مقایسه با شبکه ResNet-101
در شکل دو نتایج روش جاری با شبکه ResNet-101 به تفکیک گروه ها نمایش داده شده است
مقایسه نتایج در مجموعه داده VG-500

مقایسه نتایج در آموزش با داده های اندک
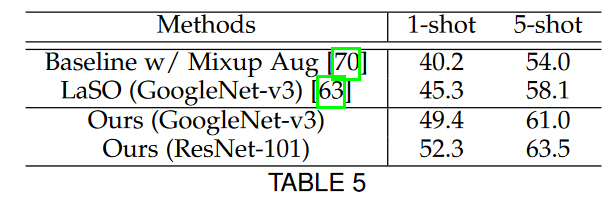
مجموعه داده Microsoft COCO
در جدول پنج نتایج اموزش شبکه با یک داده اموزش و هم چنین پنج داده اموزش برای گروه های جدید در مجموعه داده coco با سایر روش ها مقایسه شده است
مجموعه داده Visual Genome 500
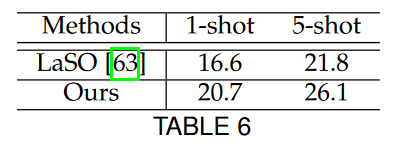
مشاهده می شود روش جاری در چالش آموزش گروه های جدید با نمونه های اموزش اندک نسبت به روش های دیگر برتری محسوسی دارد.
پژوهش فوق با ترکیب عملیات ها و تفاسیر آماری از داده ها و ترکیب آن ها با معماری های جدید شبکه عمیق نتایج قابل قبولی را کسب کند. نقطه ضعف این پژوهش را می توان در پیچیدگی های اجرایی آن دانست.



